ジェネラティブエージェンツの大嶋です。
「AIエージェントキャッチアップ #27 - Second Me」という勉強会を開催しました。
generative-agents.connpass.com
アーカイブ動画はこちらです。
Second Me
今回は、自分自身のAIを作り上げる「Second Me」について、公式ドキュメントを読んだり動かしたりしてみました。
Second MeのGitHubリポジトリはこちらです。
論文はこちらです。
今回のポイント
Second Meの概要
Second Meは、自分のプロフィールや記憶のデータをもとに、自分のようにモデルをファインチューニングするというプロジェクトです。
「自分の記憶をもとにモデルをファインチューニングして自分をAI化したい」というアイデアは定番ですが、まさにそのアイデアに取り組んだ例です。
Second Meの起動
実際にSecond Meを動かしてみました。
GitHubのREADME.mdに記載の手順を進めると、以下のWeb画面が表示されました。
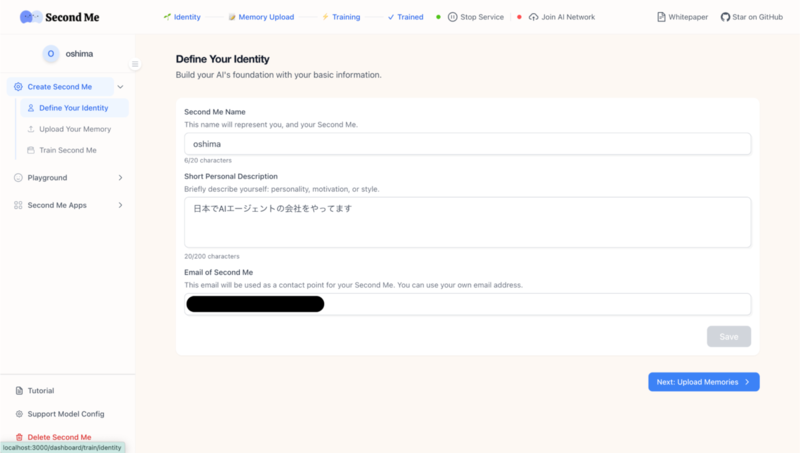
プロフィール・記憶の入力
まずは簡単なプロフィールの入力が求められます。
続いて、記憶をアップロードしていきます。
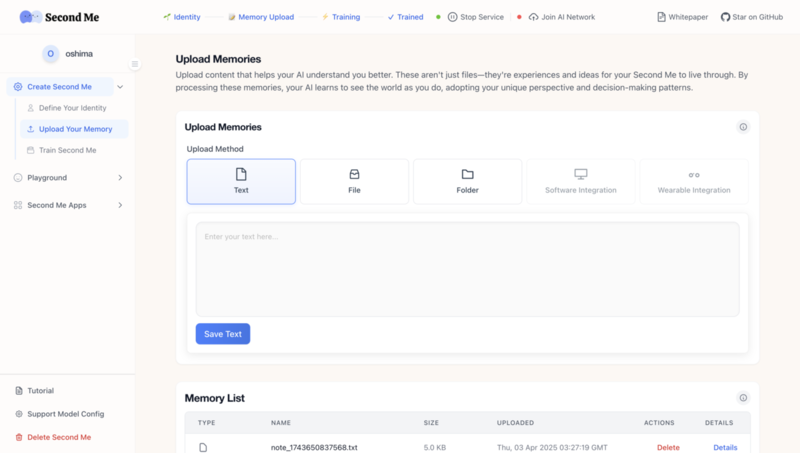
今回は例として、AIエージェントキャッチアップのconnpassページを3つ、Jina AIのReader APIでテキスト化してアップロードしました。
ちなみにSecond Meのソースコードを参照すると、画像ファイルや音声ファイルにも対応していそうでした。
学習
記憶のアップロードが完了したら、学習に進みます。 ベースモデルとしてQwen2.5-0.5B-Instructを選択して、学習を実行しました。
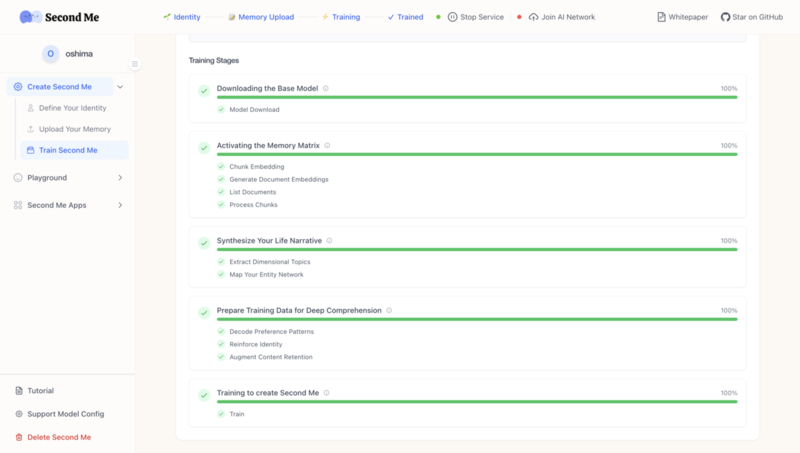
上記の学習の画面では、実際の学習(ファインチューニング)に入る前に、
- 記憶のデータをチャンク化したりベクトル化したりする
- 記憶をストーリー化する
- 学習データを作成する
といった処理が実行されているようでした。
これらの処理ではLLMとしてOpenAIのAPIを使用します。 記憶のデータをOpenAIのLLMで学習データとして整理して、その学習データをもとにQwen2.5をファインチューニングする、ということです。
「自分の記憶をもとにモデルをファインチューニングして自分をAI化したい」というアイデアを実現するには、記憶をいかに学習データとして整理するかが重要なはずです。 その点でSecond Meには様々な工夫が施されていることが垣間見えました。 工夫の内容から、個人的にはRagasの合成テストデータ生成を想起しました。
今回は記憶としてアップロードしたデータが非常に少なかったので、ファインチューニングは30分ほどで完了しました。
結果
学習が完了すると、プレイグラウンドでモデルとチャットすることができます。
試しに「日本語で自己紹介して」と言うと、以下の結果が得られました。
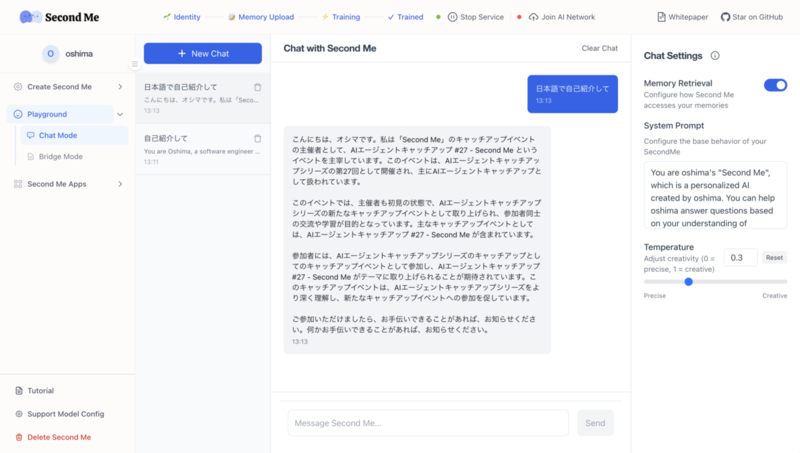
この出力の文章は日本語としては微妙ですが、記憶自体はある程度反映されていますね。
その他の機能
Second Meには他にも、作成したモデルにロールプレイさせる機能や、AIをネットワークに参加させる機能もあります。
また、「Second Tinder」「Second LinkedIn」など、様々な「Second X」機能が今後公開予定とのことです。
Second Meの機能は以下のドキュメントにもまとまっているので、興味があれば参照してみてください。
次回のご案内
以上、今回は「Second Me」をキャッチアップしました。
次回は「AIエージェントキャッチアップ #28 - Graphite」ということで、AIエージェントのイベント駆動フレームワーク「Graphite」がテーマです!
generative-agents.connpass.com
ご興味・お時間ある方はぜひご参加ください!
また、その次の回以降のテーマも募集しているので、気になるエージェントのOSSなどあれば教えてください!